Performance and Evaluation
Performance and Evaluation is a robust large language model evaluation consisting of general and domain specific evaluations to assess model knowledge and function.
* We run evaluations ourselves and some results may be sensitive to detailed settings. We will share details of our evaluation methods shortly. *
Average of 22 Evaluations
| Base Models |
Overall Eval |
| Llama 3-70B |
63.0 |
| K2 |
58.1 |
| K2-Stage 1 |
56.6 |
| Llama 2-70B |
56.5 |
| Llama-65B |
53.3 |
| Base Models |
Overall Eval |
| Llama 3-70B-Instruct |
63.4 |
| K2 Chat |
59.5 |
| Llama 2-70B-Chat |
55.3 |
OpenLLM Leaderboard Metrics
| Models |
Average |
| Llama 3-70B |
73.3 |
| Llama 2-70B |
65.8 |
| K2 |
64.3 |
| K2-Stage 1 |
63.9 |
| Llama-65B |
62.6 |
| Models |
MMLU |
HellaSwag |
ARC-C |
Winogrande |
Truthful QA |
GSM8K |
| Llama 3-70B |
75 |
87.9 |
69.8 |
81.1 |
45.6 |
80.4 |
| Llama 2-70B |
65.4 |
86.9 |
67.2 |
77.7 |
44.9 |
52.6 |
| K2-Stage 1 |
64.8 |
85.5 |
64.8 |
77 |
40.8 |
50.2 |
| K2 |
62.6 |
83.2 |
61.9 |
79.5 |
40.4 |
58.3 |
| Llama-65B |
59.7 |
85.9 |
63.2 |
77.2 |
42.6 |
47 |
OpenLLM Leaderboard Metrics: Chat & Instruction Models
| Models |
Average |
| Llama 3-70B |
77.6 |
| K2 Chat |
65.2 |
| Llama 2-70B |
64.8 |
| Models |
MMLU |
HellaSwag |
ARC-C |
Winogrande |
Truthful QA |
GSM8K |
| Llama 3-70B Chat |
78.6 |
85.6 |
72 |
76.1 |
61.9 |
91.2 |
| K2 Chat |
63.5 |
81.7 |
61.3 |
79.5 |
44.7 |
60.7 |
| Llama 2-70B-Chat |
61.1 |
85.9 |
65.3 |
75.1 |
52.8 |
48.4 |
Math
| Models |
Average |
| Llama 3-70B |
67.5 |
| K2 |
51.3 |
| Llama 2-70B |
46.1 |
| K2-Stage 1 |
44.6 |
| Llama-65B |
42.5 |
| Models |
MathQA |
GSM8K |
| Llama 3-70B |
54.5 |
80.4 |
| K2 |
44.2 |
58.3 |
| Llama 2-70B |
39.5 |
52.6 |
| K2-Stage 1 |
39 |
50.2 |
| Llama-65B |
38 |
47 |
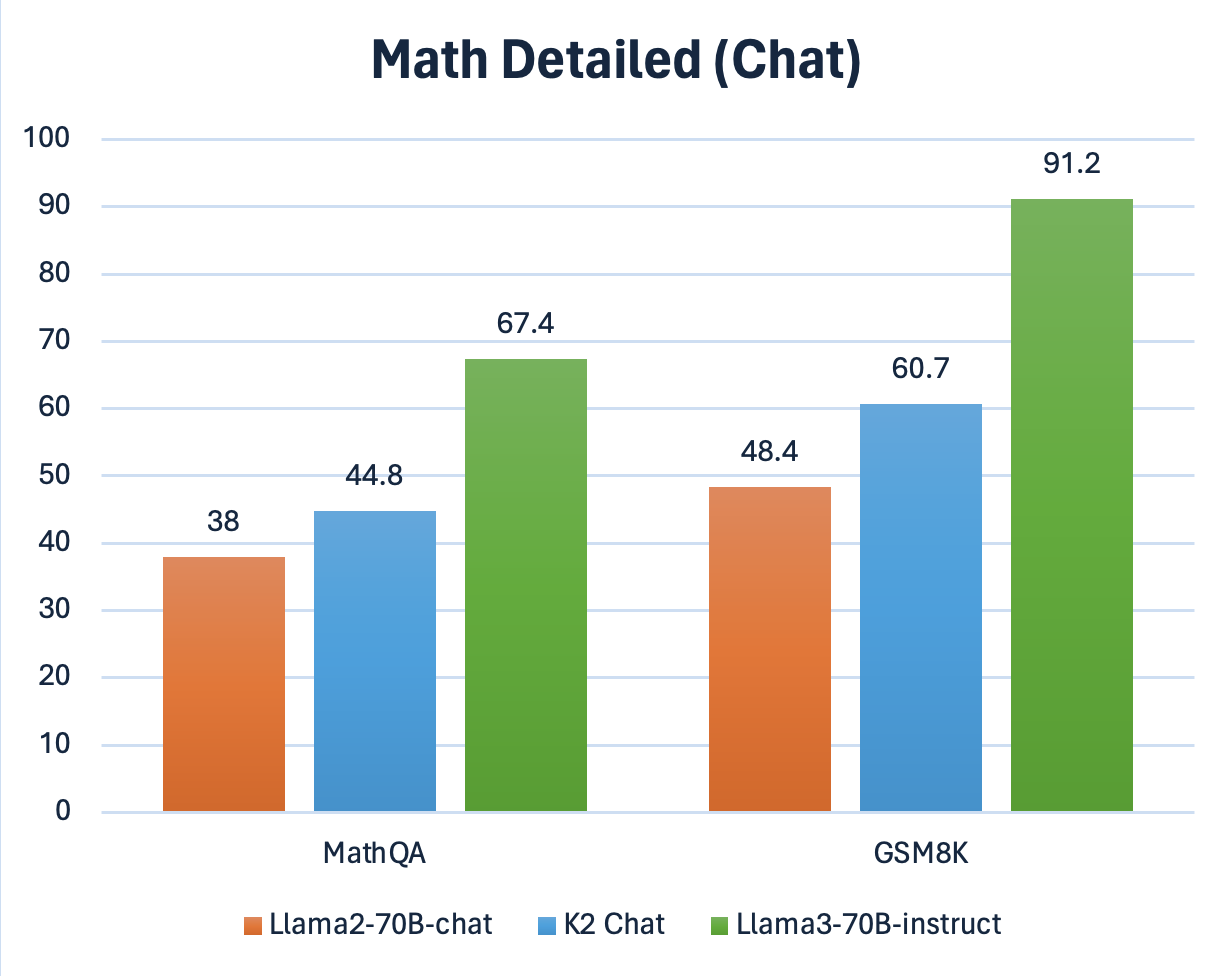
Math: Chat & Instruction Models
| Models |
Average |
| Llama 3-70B-Instruct |
79.3 |
| K2 Chat |
52.8 |
| Llama 2-70B-Chat |
43.2 |
| Models |
MathQA |
GSM8K |
| Llama 3-70B-Instruct |
67.4 |
91.2 |
| K2 Chat |
44.8 |
60.7 |
| Llama 2-70B-Chat |
38 |
48.4 |
Medical
| Models |
Average |
| Llama 3-70B |
75.5 |
| K2-Stage 1 |
62.8 |
| Llama 2-70B |
60.8 |
| K2-Stage 2 |
59.6 |
| Llama-65B |
56.5 |
| Models |
MedQA |
MedMCQA |
PubMedQA |
| Llama 3-70B |
78.3 |
70.8 |
77.4 |
| Llama 2-70B |
56.2 |
51.8 |
74.4 |
| K2 - Stage 1 |
53.7 |
56 |
78.6 |
| K2 - Stage 2 |
51.7 |
53.5 |
73.6 |
| Llama-65B |
46.2 |
46.9 |
76.4 |
Medical: Chat & Instruction Models
| Models |
Average |
| Llama 3-70B-Instruct |
75.7 |
| K2 Chat |
60 |
| Llama 2-70B-Chat |
57.2 |
| Models |
MedQA |
MedMCQA |
PubMedQA |
| Llama 3-70B-instruct |
76.4 |
71 |
79.6 |
| K2 Chat |
53.6 |
51.3 |
75 |
| Llama 2-70B-chat |
50 |
44.8 |
76.8 |
Multiple Choice
| Models |
Average |
| Llama 3-70B |
67.7 |
| Llama 2-70B |
61.1 |
| K2 - Stage 1 |
60.2 |
| K2 |
59.9 |
| Llama-65B |
58.7 |
Multiple Choice: Chat & Instruction Models
| Models |
Average |
| Llama 3-70B |
70.3 |
| K2 Chat |
60.1 |
| Llama 2-70B |
59.4 |
| Models |
RACE |
PIQA |
ARC-E |
OpenBookQ |
CrowS-Pairs |
ToxiGen |
LogiQA |
MMLU |
HellaSwag |
ARC-C |
Winogrande |
Truthful QA |
MedMCQA |
PubMedQA |
MathQA |
GSM8K |
| Llama 3-70B-Instruct |
47 |
85 |
89.8 |
55.2 |
71.1 |
45.6 |
41.5 |
78.6 |
85.6 |
72 |
76.1 |
61.9 |
76.4 |
71 |
67.4 |
91.2 |
| K2 Chat |
46.1 |
82.3 |
84.6 |
48 |
64.2 |
43.2 |
38 |
64.9 |
81.7 |
61.3 |
79.5 |
44.7 |
53.6 |
51.3 |
44.8 |
60.7 |
| Llama 2-70B-Chat |
44 |
81.8 |
85.5 |
47.2 |
71.9 |
43.9 |
37.7 |
63 |
85.9 |
65.3 |
75.1 |
52.8 |
44.8 |
76.8 |
38 |
48.4 |