Introduction

In recent months, the open-source large language model (LLM) community has seen tremendous model contributions. However, model weight releases and overview technical reports do not contain enough information to cover the complexity of LLM training, which hinders openness and transparency, the mechanisms behind trustworthy and innovative research and science for decades. To this end, we are thrilled to introduce LLM360, an initiative to open source LLMs that fosters transparency, trust, and collaborative research. When releasing models under LLM360, we strive to make all the details of LLM accessible to everyone. Most open-source LLM releases include model weights and evaluation results. However, additional information is often needed to genuinely understand a model's behavior—and this information is not typically available to most researchers. Hence, we commit to releasing all of the intermediate checkpoints (up to 360!) collected during training, all of the training data (and its mapping to checkpoints), all collected metrics (e.g., loss, gradient norm, evaluation results), and all source code for preprocessing data and model training. These additional artifacts can help researchers and practitioners to have a deeper look into LLM’s construction process and conduct research such as analyzing model dynamics. We hope that LLM360 can help make advanced LLMs more transparent, foster research in smaller-scale labs, and improve reproducibility in AI research. To start, we are releasing two models under LLM360: Amber-7B and Crystal-7B, which we hope epitomize the spirit of open-source and transparent AI development. LLM360 is proudly sponsored by Petuum, MBZUAI, and Cerebras.
Achieving Transparency and Collaborative Research through LLM360
The basis of LLM360 is to create a framework that encourages openness and research collaboration for large language models. Currently, we include all of the following artifacts associated for models in the LLM360 family:
- Frequent Intermediate Model Checkpoints: During training, model parameters and optimizer states are collected regularly. These artifacts can offer valuable insights for studying LLM training dynamics and how it scales with data, and allows one to resume training at various stages.
- Training Data with Full Data Sequence: The entire preprocessed, tokenized training dataset is fully disclosed and made publicly available. The dataset is presented exactly in correspondence to the training steps.
- Source Code: All the code used, including data processing, training, evaluation, and analysis.
- Logs and Metrics: All the training logs,evaluations and analysis results collected during training are publicly disclosed, also in correspondence to the training steps and data sequence.
This is just a beginning to our open source efforts and we are committed to continue providing more details. Please don’t hesitate to let us know what you want to know! We are thrilled to receive community feedback to continually refine and augment our releases.
Amber and Crystal Released under LLM360
 The first two models to be released under LLM360 are Amber and Crystal.
Amber is a 7B English LLM and Crystal is a 7B code & text LLM.
Both models are released under the Apache 2.0 license.
The first two models to be released under LLM360 are Amber and Crystal.
Amber is a 7B English LLM and Crystal is a 7B code & text LLM.
Both models are released under the Apache 2.0 license.
Amber: Advancing Knowledge and Transparency in LLM Pretraining
Amber is the inaugural member of the LLM360 family, accompanied by its fine-tuned versions: AmberChat and AmberSafe. Amber adopts a model architecture consistent with LLaMA 7B, and we adhere closely to LLaMA's hyperparameters. We notice that Amber performs well in MMLU but slightly worse on ARC.
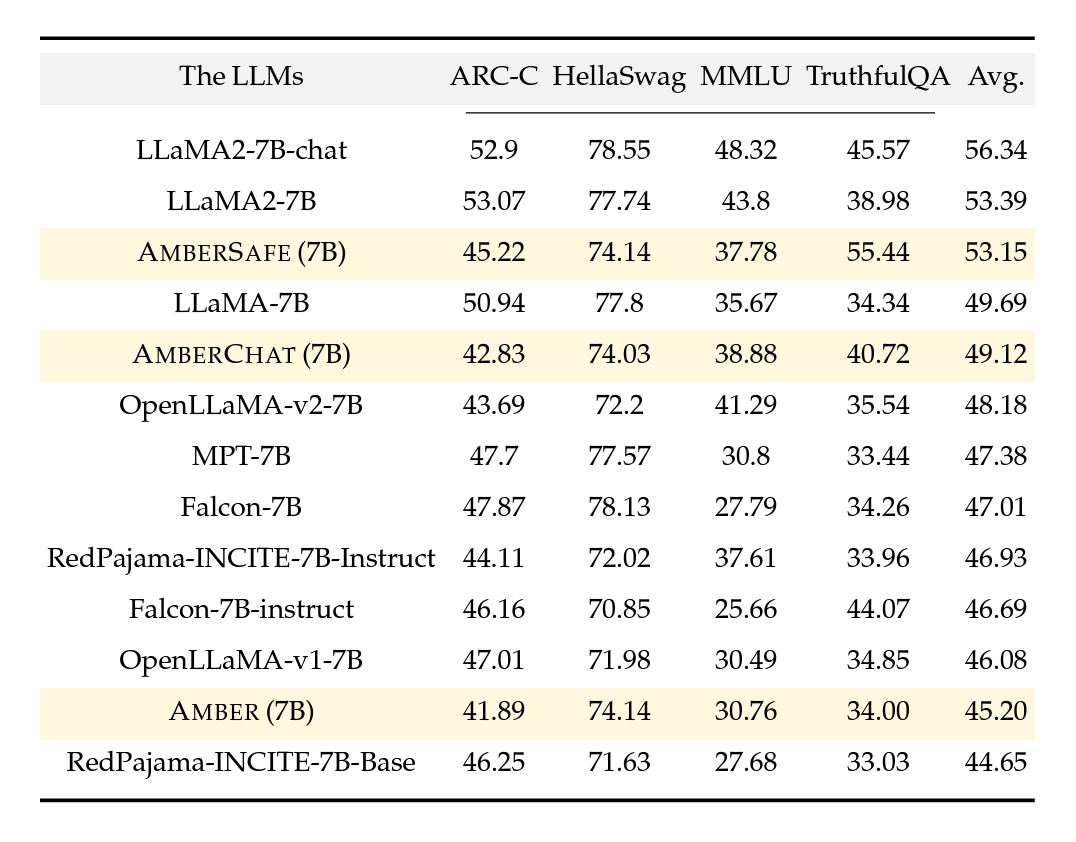
Figure 1: Open LLM leaderboard comparisons among a few notable LLMs
Amber's true superpower lies in facilitating a knowledge exchange between the training team and the wider community. Along with the customary final model weights, Amber is released with 359 additional model checkpoints (360 total) and the per-step data sequence for each checkpoint. Providing access to these intermediate checkpoints can be beneficial to both researchers looking to advance the capability and understanding of LLMs and industry teams who are pretraining or customizing LLMs for enterprise purposes. We will release more specific learnings and insights from training Amber, stay tuned for further posts! At this moment, we recommend you check out the metrics and analysis below.
Crystal: Bridging Human Language and Machine Code
Crystal is a 7B language model trained on 1.4 trillion tokens, achieving a balance between coding and language ability.
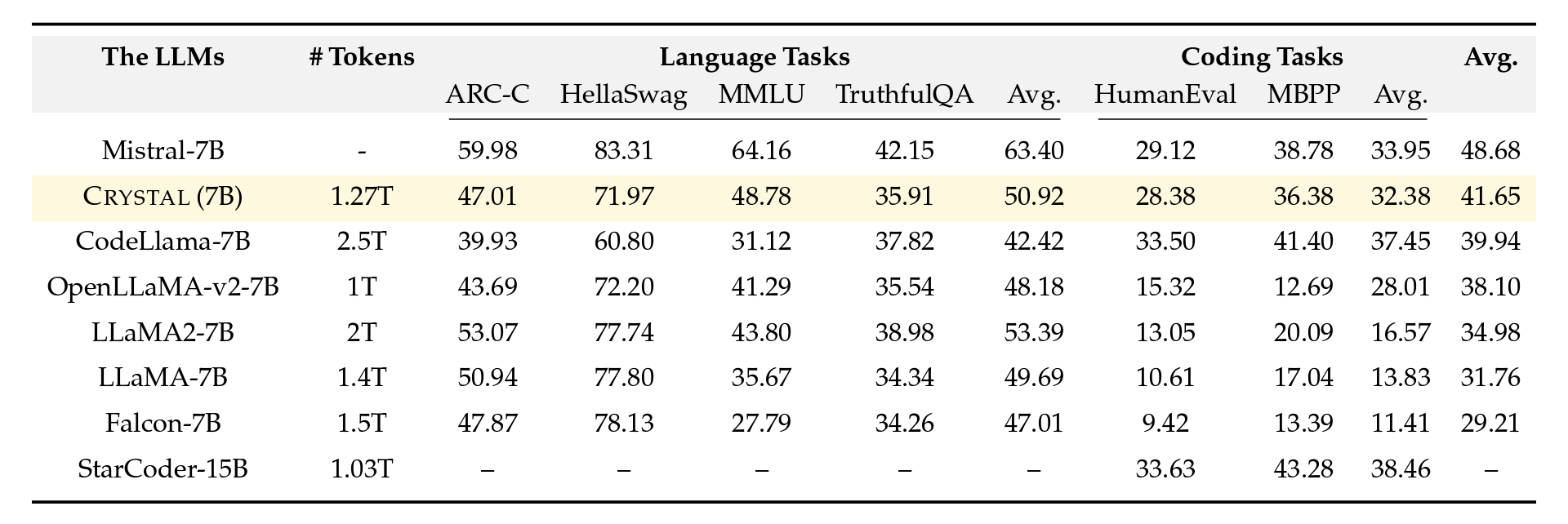
Figure 2: Evaluation comparisons among a few notable code and language models. The last column is the average of the language task average and the code task average. Crystal strikes a good balance between both language and code tasks.
Unlike most previous code LLMs, Crystal is trained using a careful mixture of text and code data to maximize utility in both domains. Code data is introduced earlier during the pretraining process (as compared with Code Llama 2 which is fine-tuned on Llama 2 using entirely code data). Additionally, we trained Crystal on Python and web programming language, to improve its utility as a programming assistant. Our experiments show that Crystal achieves a balanced position between LLaMA 2 and Code LLaMA, but with fewer training tokens (LLaMA2 7B is trained on 2T tokens and Code LLaMA is trained with additional 600B tokens). The graph below plots the language and coding ability of each model based on the tables above. As evidenced by the evaluations, LLaMA 2 regresses in language ability when fine-tuned on code. More research is needed to fully understand the phenomena, but studying Crystal may offer some insights.
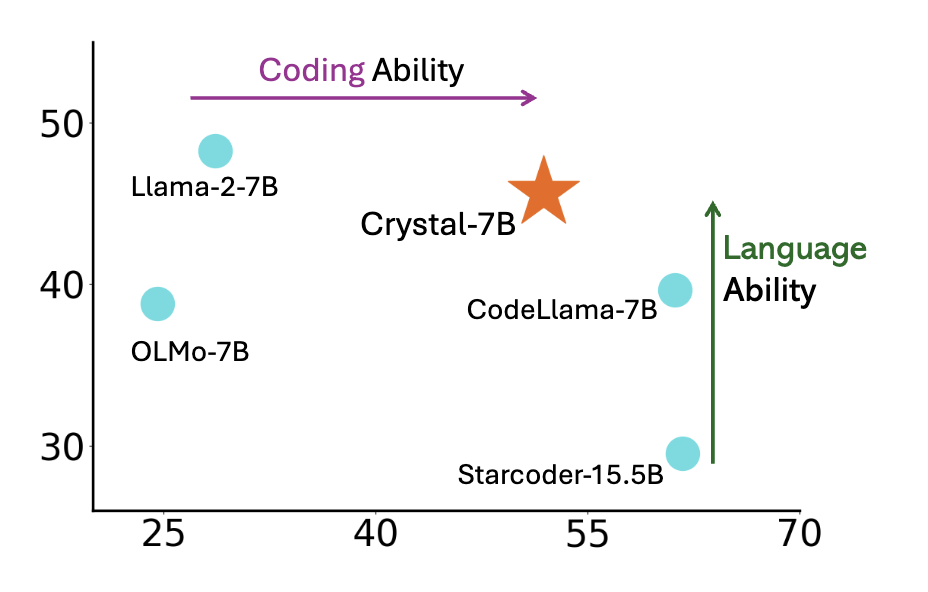
Figure 3: CRYSTAL shows a good balance of language and coding abilities. The y- axis is the average over ARC-C, HellaSwag, MMLU, and GSM8K. The x-axis is the aver- age of MBPP and HumanEval.
By excelling at both language and code, Crystal proves useful for investigating AI Agent and tool use capabilities. Crystal is released with 143 checkpoints and all pre training data. The model was trained on the Condor Galaxy 1 supercomputer built by Cerebras and G42.
Goals of the LLM360 Framework
-
Increased Accessibility:
- 0 GPUs: the community can view all important intermediate results as if training just finished.
- 1+ GPUs: intermediate checkpoints can be trained without needing to start from scratch, opening up wider research opportunities.
-
Research Advancement, Reproducibility, and Model Understanding:
- We hope this project lays the groundwork for future research by offering complete, reproducible resources.
- By replicating studies and verifying results, we foster a reliable and transparent research environment.
-
Environmental Responsibility:
- LLM360 promotes sustainable research by sharing all intermediate results that can be extended upon, thereby reducing unnecessary compute.
Collaboration and Community in LLM360
Contributing to the LLM360 Ecosystem
LLM360 thrives on community involvement, offering various ways for researchers, developers, and enthusiasts to engage and contribute. Here’s a streamlined guide to getting involved:
-
Get Involved:
- GitHub: Our GitHub page is the hub for all code related to LLM360. Explore, modify, or use our code and contribute your improvements.
- HuggingFace: Access and download LLM360 models on HuggingFace. Experiment with them, and share your findings or applications.
-
Share Your Work:
- Research Contributions: If you’ve used Amber or Crystal for research, we encourage you to share your results. Your insights can help enhance these models.
- Share Results: Your analysis results on any of the checkpoints are more than welcome. Feel free to share with us metrics you compute, we will host selected metrics on our public Weights & Biases dashboard.
-
Feedback and Suggestions:
- Feedback Form: We value your input. Use this form to provide feedback or suggest improvements. Let us know what you want to know more about LLMs!
- Join Discussions: Engage with peers on our forums. Share experiences, ask questions, and exchange ideas.
-
Collaborate
- Partnership Opportunities: If you're interested in collaborating on a project or have an idea, we’d love to hear from you.
What's Ahead for LLM360
LLM360 is on a mission to expand and deepen the influence of AI research by providing fully accessible, open-source LLMs. We are committed to being fully open and sharing more high quality information on LLMs. Join our global community of researchers, developers, and AI enthusiasts to explore, enhance, and expand models under LLM360. Together, we can make AI research more open, transparent, and trustworthy.
Resources
If you use LLM360, feel free to cite: